
Data augmentation for Natural Language Understanding
By Sonia Ratsiandavana - Sep 4, 2019
LINAGORA is a French company, specializing in open source software. One of its current projects is the development of the open source smart vocal assistant LinTO. LinTO helps employees organize and carry out meetings: thanks to its Natural Language Understanding system, it can answer voice commands.
When training a natural language recognition engine, one of the major problems we have to tackle is data scarcity. A large training corpus is generally needed to improve these systems. The task of manually building a corpus is time-consuming and requires a lot of human resources. In this article, we describe the method we developed to create a data augmentation module, able to automatically create alternative commands from a small existing french corpus.
The reference corpus
For this project, the reference corpus we use is composed of several commands annoted manually beforehand in Tock, an open-source platform for bot building. It allows us to specify existing entities and attribute an intent to each command. An intent is the purpose of the user when formulating the command, and entities are the relevant key words that can be found in a given sentence (such as location, time ect.).
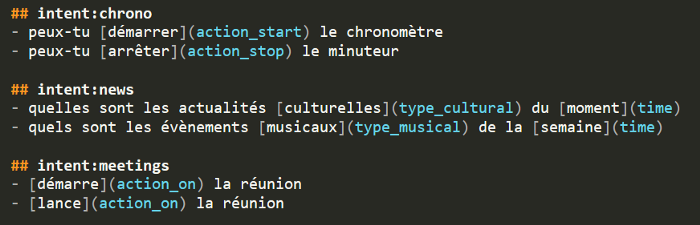
Command samples from the annotated reference corpus
Command Types
In our corpus, we identified two categories of commands:
- Action commands: this category covers sentences that require the execution of a certain action. For instance: “allume la lumière” or “peux-tu démarrer le chronomètre ?”.
- Information commands: it is a category that contains sentences that query the information system. For instance: “quelle est la météo à Toulouse” or “donne-moi le niveau de pollution à Kyoto”.
In the action command category, we can find two types of sentences:
- Imperative sentences: these include a verb in the imperative form (“stoppe le chronomètre”)
- Questions: these are requests expressed in the form of questions (“peux-tu démarrer le chronomètre ?”)
The information command category contains numerous subcategories:
- Close-ended questions: this kind of question can be answered with “yes” or “no” (“est-ce qu’il va pleuvoir ?”, “Paris est-elle polluée ?”)
- Open-ended questions: these require a more developed answer (“qui sont les participants à la réunion ?”, “quel est le niveau de pollution à Paris ?”)
- Nominal sentences: these are characterized by the absence of a verb (“actualité culturelle”, “météo à Toulouse”)
- Imperative sentences: these include a verb but are different from imperative action commands (“donne-moi la date”, “donne-moi le titre de la réunion”). They always ask for a piece of information.
According to the type of command identified by our module, the syntactic structures of the generated alternative sentences vary: for instance, for the action command “allume la lumière”, we cannot generate alternative commands such as “quelle est la lumière ?” or “donne-moi la lumière”. That would change the original meaning of the sentence. However, for the information command “météo à Toulouse”, we could say “quelle est la météo à Toulouse ?” or “donne-moi la météo à Toulouse”.
Data Augmentation Module: a system based on a rule-based grammar
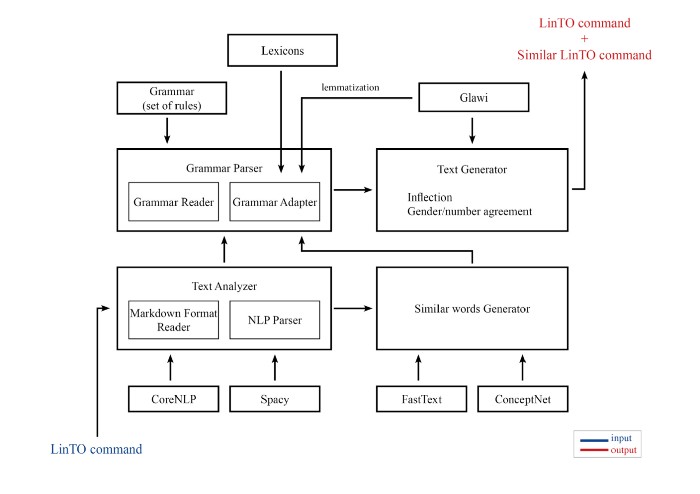
The different components and resources of the data augmentation module
When processing a command, our system starts by identifying its type (action or information, and sub-categories of questions) by using certain clues in its syntactic structure. The system then retrieves the most important meaningful units in the sentence thanks to Natural Processing Tools like CoreNLP and Spacy Python. In the action command “peux-tu démarrer le chronomètre”, it would keep the verb that describes the action to execute (“démarrer”) and the object of this action (“chronomètre”). In the information command “quelle est la température à Paris”, it would keep the noun (“température”) and the location (“Paris”). These key words will be kept or used to generate similar words.
The next step is therefore to generate new syntactically and semantically correct alternative commands.
To create our paraphrasing system we used a rule-based grammar: a system that allows us to create a set of rules in a formal language. These rules are used to generate strings that follow the syntax we set.
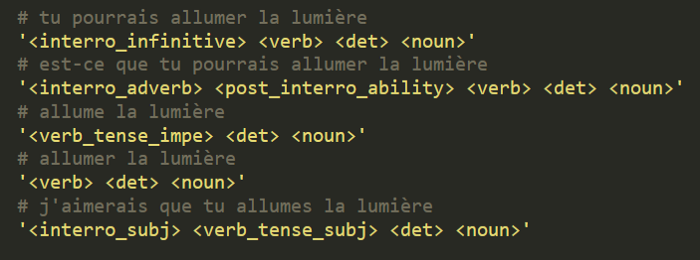
Examples of rules to generate alternative “action” commands
Each rule is composed of several tags that match certain words or expressions that we want to find in the final generated sentence.
For instance, the “interro_infinitive” tag refers to a list of expressions that are commonly followed by an infinitive verb, whereas the “interro_subj” tag refers to expressions that are followed by verbs conjugated in the subjunctive tense. These kind of expressions are listed in lexicons that we manually created (“je veux que”, “c’est quoi”, “peux-tu” etc.). The requested expression is randomly chosen in the corresponding list.
Tags that mention verbs or nouns refer to the words retrieved in the input command, or similar words that we generate from them. Tags which begin with the expression “verb_tense” indicate that the verb has to be conjugated according to the specified tense (we currently use the imperative or the subjunctive tense). All of these tags are independent and can be reused to create other rules.
There is a specific set of rules for each command category: as we said before, each kind of command has its own syntactic structure and an action command will not be paraphrased in the same way as an information command. We can choose the number of alternative sentences we want to generate: for each generation, the new syntactic structure (represented by a rule) is also randomly chosen in the set of rules.
Words and inflection
Once the module determines the new syntactic structure it wants to apply, it needs to address the issues of conjugation and gender/number agreement. In morphology, the different forms that a word can take are called its “inflected” forms. A word’s inflected form depends on the morphological properties of the word it is attached to. The word that undergoes the transformation is called the “dependent” and the word that leads it is called the “head”.
For instance, if the input command is “quels sont les articles culturels du moment ?”, if we replace the noun “articles” (masculine-plural) by the synonym “nouvelles” (feminine-plural), the new correct syntactic structure would be “quelles sont les nouvelles culturelles du moment ?”.
For this task, we used GLAWI, an electronic dictionary created by Franck Sajours, Nabil Hathout and Basilio Calderone. Glawi is a structured and machine-readable version of the Wiktionnary. It contains lots of linguistically relevant information about words, including their inflected forms.

Inflected forms of the adjective “culturel” in GLAWI
We used this information to get the appropriate form of the dependent according to its head.
Generation of equivalent words
To bring variety to our generated commands, we cannot simply change the syntactic structure of the sentence and reuse the existing words of the input command. We had to generate words that could be used in the same context, such as synonyms, hyperonyms (a word whose meaning includes the meaning of more specific words → “voiture” is the hyperonym of “limousine”), hyponyms (the opposite → “limousine is the hyponym of “voiture”) or cohyponyms (“Toulouse” and “Paris” are both hyponyms of “ville”).
We used two methods to generate equivalent words:
- Equivalent words from the input file: we reused instances belonging to the same entity and non annotated words from the same intent to recombine them.
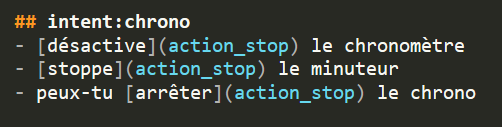
Instances of the entity “action_stop”
For example, for the input command “désactive le chronomètre”, where “désactive” comes from the entity “action_stop”, we can retrieve the synonyms “stopper” and “arrêter”. We can also take the synonyms of the noun “chronomètre” in the other commands that belong to the intent “chrono”, such as “minuteur” and “chrono”.
- Equivalents from external tools: we used ConceptNet, a semantic network that gives synonyms, hyperonyms, and other terms related to an input word. We also used FastText, an open-source library that uses words embeddings (a method that represents words as vectors to evaluate how close two words are to each other).


Examples of synonym and hyperonym of “vidéoconférence” in ConceptNet
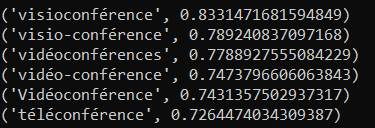
Examples of equivalent words for “vidéoconférence” in FastText
Some examples
To conclude the presentation of our data augmentation module, here are a few examples of generated commands:
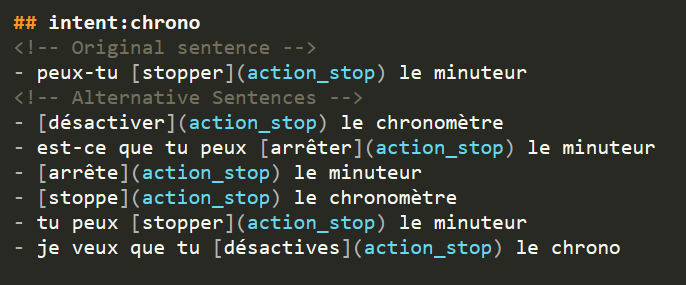
Samples of generated action commands
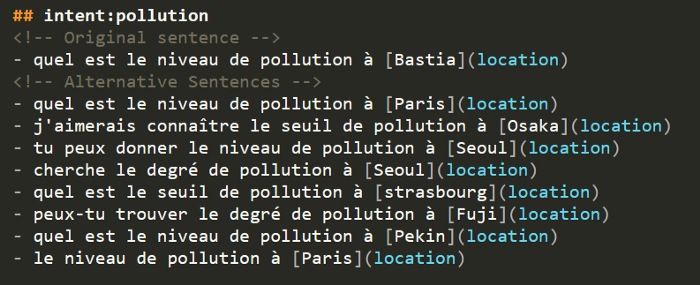
Samples of generated information commands
What’s next?
French grammar is rich: we would need to add new rules to process other syntactic structures. To improve accuracy, the user will also have the ability to manually check similar words automatically generated by ConceptNet and FastText.
Accessibility
visibility_offDisable flashes
titleMark headings
settingsBackground Color
zoom_outZoom out
zoom_inZoom in
remove_circle_outlineDecrease font
add_circle_outlineIncrease font
spellcheckReadable font
brightness_highBright contrast
brightness_lowDark contrast
format_underlinedUnderline links
font_downloadMark links
Reset all optionscached

We use cookies on our website to provide you with the most relevant experience by remembering your preferences and repeating your visits.
Cookies allow us to personalise content and advertisements, provide social media features and analyse our traffic. We also share information about the use of our site with our social media, advertising and analytics partners, who may combine this with other information you have provided to them or that they have collected through your use of their services.
By clicking "Accept All" you consent to the use of ALL cookies.
Cookies allow us to personalise content and advertisements, provide social media features and analyse our traffic. We also share information about the use of our site with our social media, advertising and analytics partners, who may combine this with other information you have provided to them or that they have collected through your use of their services.
By clicking "Accept All" you consent to the use of ALL cookies.
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely necessary for the proper functioning of the website. This category includes only those cookies that provide the basic functionality and security features of the website. These cookies do not store any personal information.
Functional cookies enable certain features to be performed such as sharing website content on social media platforms, collecting comments and other third party features.
Performance cookies are used to understand and analyse key performance indicators of the website, which helps to provide a better user experience for visitors.
Les cookies analytiques sont utilisés pour comprendre comment les visiteurs interagissent avec le site web. Ces cookies permettent de fournir des informations sur les mesures du nombre de visiteurs, le taux de rebond, la source de trafic, etc.
Advertising cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors to websites and collect information to provide personalised ads.
Other uncategorised cookies are those that are being analysed and have not yet been categorised.