
Tuning of parameters for decoding in automatic speech recognition
By Samir Tanfous - Jan 29,
This article aims to show you the impact of hyper parameters on decoding performance for automatic speech recognition (ASR) systems.
I work as a Data Scientist in LINAGORA’s R&D Labs, on LinTO project, which is a smart open-source voice based assistant for enterprises’ meetings.

LinTO, presented in the CES event at Las Vegas in 2019, January
What is LinTO ?
The LinTO project is developed by Linagora’s R&D teams. This research project is a French PIA “Grands Défis du Numérique” funded by BPI, and supported by SGPI “Secrétariat Général pour l’Investissement” and DGE “Direction Générale des Entreprises”. It is part of Linagora’s commitment to:
- Promote Open Source, by offering free code source.
- Respect users’ private data, by performing automatic speech recognition without sharing user data in Cloud infrastructures, unlike other personal assistant such as Alexa or Google Home.
The LinTO device will have different functionalities:
- Automatic Speech Recognition (ASR): Transforming an audio signal of speech into text.
- Natural Language Understanding (NLU): Detecting intentions where the objective will be to carry out concrete actions such as “Turn off the light in the room” or “Add a meeting to my agenda with Jean-Pierre on Thursday at 3pm”. In the last example, LinTO will be able to connect to the OpenPaaS open source collaborative platform to add an appointment to the collaborator’s calendar.
- Quality of service with embedded audio acquisition and signal processing (denoising, echo cancellation…).
- Automatic summary of professional meetings: Producing a summary of a meeting with the keywords of the conversation.
As far as my work is concerned, it focuses mainly on automatic speech recognition.
One of the main objectives of LinTO is speech recognition. From a one-dimensional audio signal of speech, how can it be transcribed into text ?
Speech to Text
Automatic speech recognition is based on 2 main phases:
– Training, based on Machine Learning techniques. The goal is to build a model from audio files, for which the text transcription is already known.
– Decoding, where the model created in the previous phase is used to find the transcription on new audio files.
In this article, we will focus on decoding. It is a very active research area, as many metrics can be used to quantify the effectiveness of decoding.
On the one hand, there is the accuracy of transcription, which is measured using WER (word error rate).
What is WER ?
It is a metric used to determine a “distance” between the reference sentence and the sentence estimated by the model.
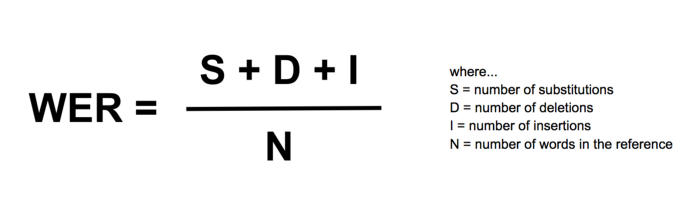
WER formula
For instance, suppose that the reference sentence (the sentence you are trying to predict) is: “this beautiful day”, but the model predicts “these day”, then you have to make a substitution (replace “these” with “this”) and an insertion (add “beautiful”) to move from the sentence predicted by the model to the reference sentence.
The number of reference words being 3, the WER is therefore (2/3)*100% = 66.7% (very bad !).
On the other hand, the efficiency of decoding can be measured by calculating the time it takes a model associated with a CPU/GPU architecture to transcribe on a given set of sentences.
This last lever point is crucial for Linagora’s applications. The goal for LinTO is to provide the most accurate transcription possible, but with the fastest possible decoding time. We are exploring many state-of-the-art ways to improve the decoding speed. One of the most promising is to parallelize the decoding algorithm using GPUs. However, the solutions we currently use run on CPUs.
In order to optimize the use of CPUs for decoding, it is possible to tune on hyperparameters (values set by a human before the algorithm is launched and not determined by the model). One of the hyper-parameters that allows to significantly modify the decoding is the “beam”.
What is the beam parameter ?
The constitution of the learning model allows to build weighted oriented graphs, which we will go through in order to decode new sentences, to find the most probable paths.
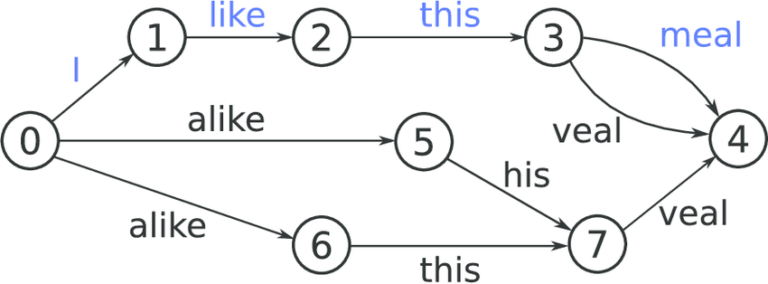
Decoding graph at word level. The weights of each transition are not indicated, but the most likely sequence is the one in blue
The graph to explore is generally very large, the path of all possible paths is done in exponential time. A naive approach is to explore all possible paths, and choose the one that maximizes the probability that the sentence you decode is maximum, but this is computationally unacceptable.
Many strategies exist to improve the search through this graph. One of them, which is simple to understand and implement, is to select the most probable N wires when you reach a node, with N fixed along the graph. This value of N corresponds to the beam parameter defined above. The smaller the beam, the fewer the number of paths to be explored for decoding, and therefore the decoding time will be reduced, but it is possible that interesting solutions will not be explored.
We wanted to test the impact of this parameter. To do this, we trained a learning model on OpenSource data from the LibriSpeech corpus, and performed decoding on test data from the same corpus. We are working on a server of 6 cores (2 threads per core). The framework we used to implement learning model and decoding part is Kaldi.

Kaldi, open source toolkit for speech recognition
Kaldi is a generic toolkit used to create automatic speech recognition systems. It’s implemented in C++ and uses a powerful library to deal with graphs, called OpenFST.
Algorithm implementations
We performed a battery of tests using Kaldi to measure the WER and decoding time on different beam values.
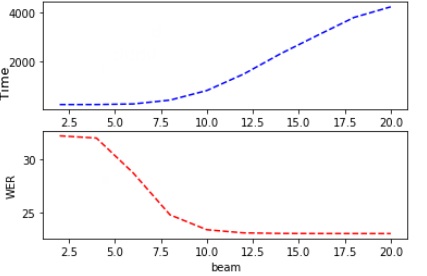
Evolution of decoding time and WER as a function of beam
We see on this graph that the decoding time increases linearly with the beam, while the WER decreases linearly until it reaches a threshold value. The choice of an interesting beam is a compromise between precision and speed. Here a value of 9 seems correct.
It is also possible to highlight the impact of the size of the models that are evaluated with the WER. In the graph below, we study the impact of the beam on the WER for different sizes of language models. The language model (LM) defines a probability distribution over a sequence of words. In the context of automatic speech recognition, the model that is mainly used is the N-gram model. It makes it possible to predict in terms of probability the appearance of a word conditioned by the previous N-1.
For example, a 3-gram model will give the probability of a word followed by a 2-word context. If it is well trained, he may, for instance, conclude that the word “soon” is more likely to appear after “see you” than the word “sentence”.
Thus, the language model is constructed by calculating the probabilities of occurrence of different groups of words, for N generally ranging from 1 to 4.
However, these language models are too expensive in terms of storage space. They increase the size of the decoding graph, and therefore, the time required to provide a transcription. They can be reduced by, for instance, limiting the size of the vocabulary or by imposing a threshold to eliminate N-grams with a too low probability (called pruning), but these techniques therefore reduce the quality of transcription, as illustrated in the graph below:
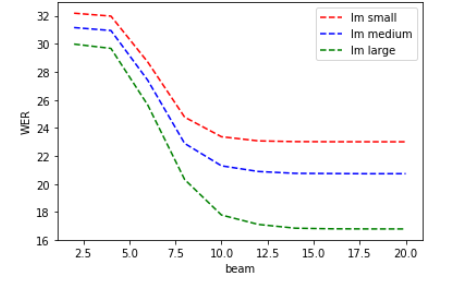
Evolution of WER as a function of beam, with different sizes of language model
There are many other hyper-parameters on which it is possible to play to improve this compromise, and this parameterization engineering is very important for the needs.
What’s next?
Most research in automatic speech recognition focuses on the implementation of new learning algorithms to improve WER, mainly based on neural networks. However, for commercial uses, it is important to remember that transcription speed is almost as important as its accuracy, imagine that a voice assistant takes several seconds or even several minutes to process an audio signal. Even with a perfect result, commercial applications would be limited. At Linagora, this is a crucial point for the customers.
Accessibility
visibility_offDisable flashes
titleMark headings
settingsBackground Color
zoom_outZoom out
zoom_inZoom in
remove_circle_outlineDecrease font
add_circle_outlineIncrease font
spellcheckReadable font
brightness_highBright contrast
brightness_lowDark contrast
format_underlinedUnderline links
font_downloadMark links
Reset all optionscached

We use cookies on our website to provide you with the most relevant experience by remembering your preferences and repeating your visits.
Cookies allow us to personalise content and advertisements, provide social media features and analyse our traffic. We also share information about the use of our site with our social media, advertising and analytics partners, who may combine this with other information you have provided to them or that they have collected through your use of their services.
By clicking "Accept All" you consent to the use of ALL cookies.
Cookies allow us to personalise content and advertisements, provide social media features and analyse our traffic. We also share information about the use of our site with our social media, advertising and analytics partners, who may combine this with other information you have provided to them or that they have collected through your use of their services.
By clicking "Accept All" you consent to the use of ALL cookies.
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely necessary for the proper functioning of the website. This category includes only those cookies that provide the basic functionality and security features of the website. These cookies do not store any personal information.
Functional cookies enable certain features to be performed such as sharing website content on social media platforms, collecting comments and other third party features.
Performance cookies are used to understand and analyse key performance indicators of the website, which helps to provide a better user experience for visitors.
Les cookies analytiques sont utilisés pour comprendre comment les visiteurs interagissent avec le site web. Ces cookies permettent de fournir des informations sur les mesures du nombre de visiteurs, le taux de rebond, la source de trafic, etc.
Advertising cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors to websites and collect information to provide personalised ads.
Other uncategorised cookies are those that are being analysed and have not yet been categorised.