
Voice Activity Detection for Voice User Interface.
By Rudy Baraglia -
As a part of a R&D team at Linagora, I have been working on several Speech based technologies involving Voice Activity Detection (VAD) for different projects such as OpenPaaS:NG to develop an active speaker detection algorithm or within the Linto project (The open-source intelligent meeting assistant) to detect Wake-Up-Word and vocal activity.
Speech is the the most natural and fundamental mean of communication that we (humans) use everyday to exchange information. Furthermore with an average of 100 to 160 words spoken per minute this is the most efficient way to share data – far exceeding typing (~40 words per minute).
The fastest typers using stenotype can reach up to 360 WPM when the fastest speaker can reach up to 630 WPM (That’s a lot of words !).
For a long time, since the beginning of the computer era to a few years ago, computer interactions were only achieved through your fingers. This paradigm changed now that technology and computational power became sufficient enough and affordable enough to allow real-time processing of signal such as speech or video-feed.
Nowadays Voice User Interface are beginning to spread to most of our daily devices like smartphone (e.g. Cortana, Siri, Ok Google, …), personal assistant (e.g. Google Home, Amazon Echo, …) or Interactive voice Response (bank, answering machine, …), with rather good performances. They work pretty much the same way: When the device ears a specific Wake-Up-Word, it captures the audio-feed, enhances it, determines if it is speech or not, then transforms the raw signal to a much relevant representation to be processed by a Speech-To-Text engine which outputs a transcription.
Let’s start with some basics in order to understand the difficulties of Voice Activity Detection.
Disclaimer: This is not a complete coverage of the matter, just some leads on existing approaches and methods that we successfully used in our projects.
Signal & Features
First thing first, let’s take a signal :
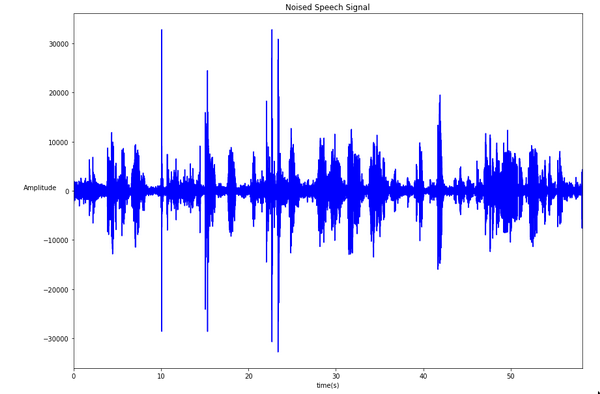
Introduction of Don Juan bragging about the virtues of tobacco.
Here it’s me pronouncing the first few sentences of Don Juan in French punctuated with various noises. We can notice that it is almost possible to guess what is speech from what’s not. This is because the background noise is very low which is the opportunity to introduce a metric: the Signal to Noise Ratio.
Signal to Noise Ratio.
Signal-to-noise ratio (abbreviated SNR or S/N) is a measure used in science and engineering that compares the level of a desired signal to the level of background noise.
SNR is defined as the ratio of signal power to the noise power, often expressed in decibels. A ratio higher than 1:1 (greater than 0 dB) indicates more signal than noise.
Wikipedia
SNR is defined as the ratio of signal power to the noise power, often expressed in decibels. A ratio higher than 1:1 (greater than 0 dB) indicates more signal than noise.
Wikipedia
This metric is important and is used as reference for VAD algorithms evaluation. Let’s take a signal with a lower SNR:
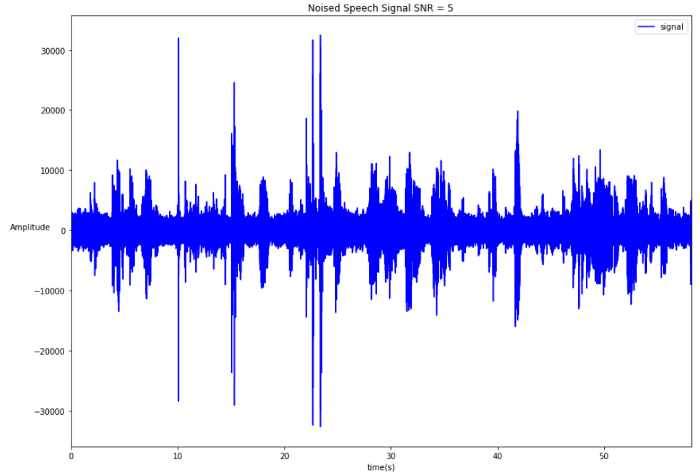
Don Juan with additive white noise.
As you can see it becomes a little bit trickier to guess where are the speech parts and impossible when the SNR goes below 0:
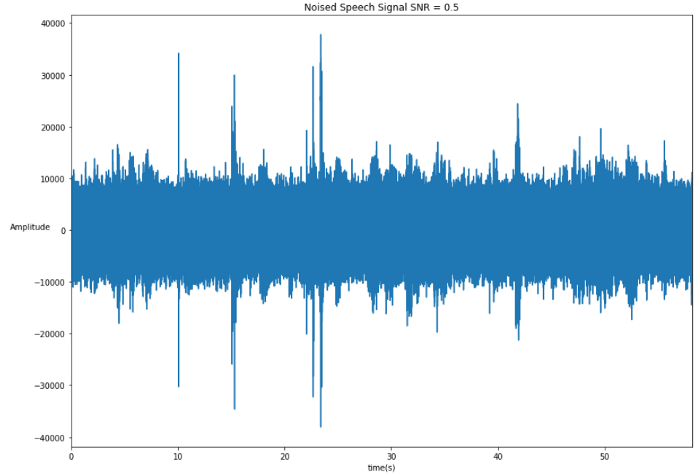
Don Juan with more additive white noise.
In that case there is still speech and you can hear it which means your brain can separate it from the noise … which means a computer should be able to do it as well.
SNR is important to know as a specification to your VAD system because it may dictate the approach you should take to have an effective algorithm. If you know that the VAD will take place in a quiet environment you may use different features than if you are recording in a plane cockpit or in a car with opened windows.
That being said let’s go back to the signal and take a look at the features we can extract from it.
Signal Analysis
In order to study the signal it is customary to divide it into sliding windows or just windows.
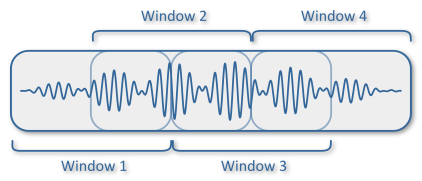
Window’s width impacts the precision of the output, wider window means a better accuracy on the frequency scale (See below) when narrower window are more precise on the time scale.
Sliding windows with overlapping are a way to mitigate side-effect for window that are straddling on both speech and non-speech frames.
We mainly use window of size 1024 (0.064s at 16000Hz) or 2048 (0.128s) as they are powers of 2 with overlapping equal to half the window.
Short-Term Energy
Short Term Energy (STE) is the most commonly used feature to discriminate Voice Activity from non-activity. It relies on the average absolute amplitude on the windows:
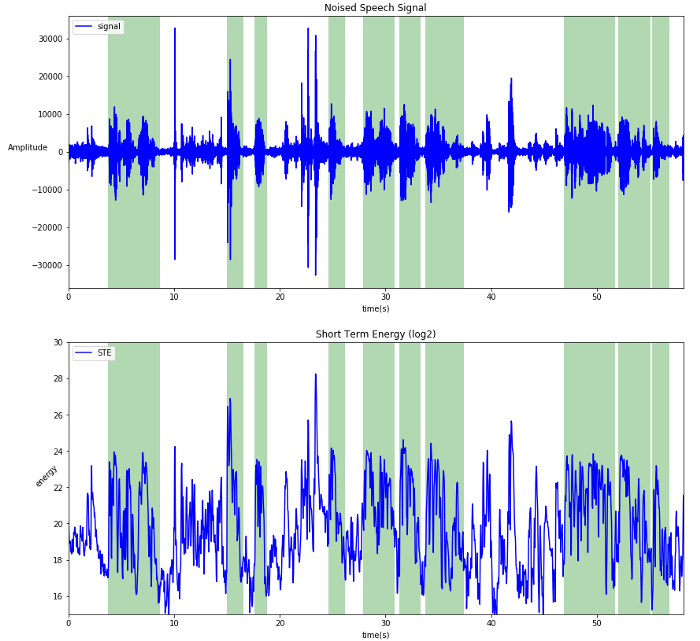
Short Term energy
Note: In green are the speech segments annotated by hand.
It is efficient for high SNR signal but loses effectiveness when the SNR drop until it become ineffective bellow 1. It also can’t discriminate speech from noises like impact noise (dropping your pen on the table), typing, air conditioner or any noise as loud or louder than human voice.
From now on we’ll be working in an other domain. The frequency domain.
Fourrier Transform
The Fourier transform decomposes a signal into the frequencies that make it up. It means that from a given audio window it returns the frequency distribution which is very interesting because the way we ear sound is by decomposing it into frequencies and human voice frequencies are well known.
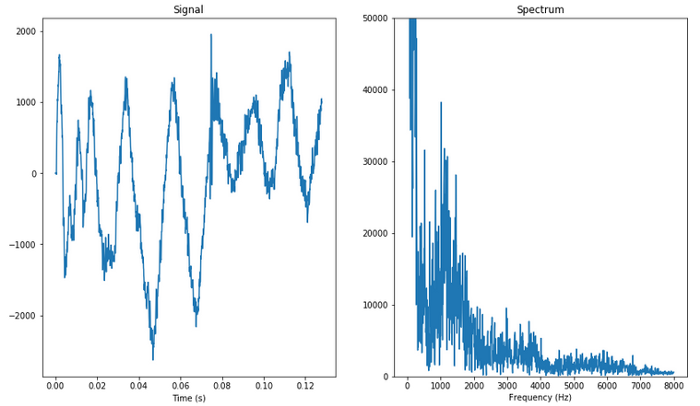
Signal to spectrum
Spectrogram
The spectrogram is the spectrum over time.
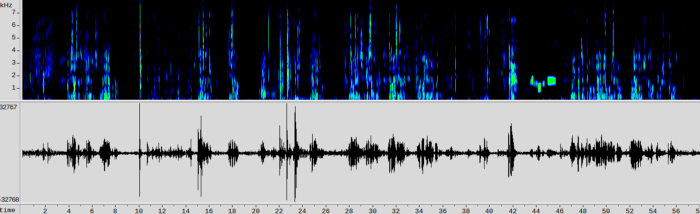
Signal to spectrum
We can clearly see that frequencies of human voice are not random and comply to a pattern.
Spectral Flatness Measure (SFM)
Spectral flatness is the measure of … the flatness of the spectrum (obviously). It is the ratio of the geometric mean over the arithmetic mean. It computes if the signal is noise-like (tend to 1) or tone-like (tend to 0) like speech.
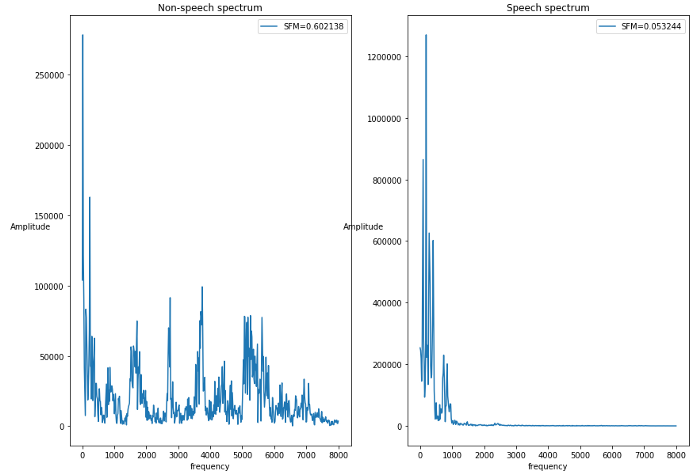
Spectral Flatness of both speech and non-speech.
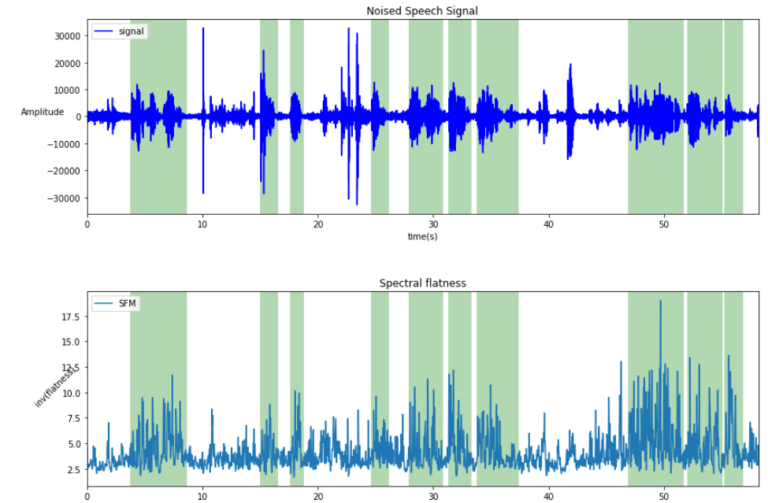
Spectral Flatness (inverted)
Dominant Frequency
Dominant frequency seeks the frequency which has the higher spectrum amplitude, the fundamental frequency. It is based on the fact that human voice has specific and known fundamental frequencies (pitch).
Human voice fundamental frequency varies between 80Hz to 180Hz for male and between 160Hz to 260Hz for female.
Children fundamental frequency is around 260Hz and a crying baby around 500Hz.
This is the frequency produced by the vocal folds.
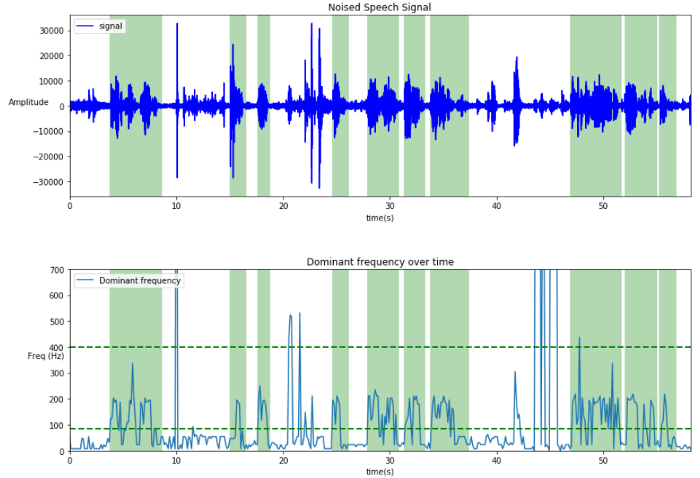
Dominant frequency
Spectrum Frequency Band Ratio
This home-brew feature combines the last two features approaches. It is the ratio of a specific frequency band amplitudes over the whole spectrum. The band’s border have been obtained through experimentation and set to [80Hz-1000Hz].
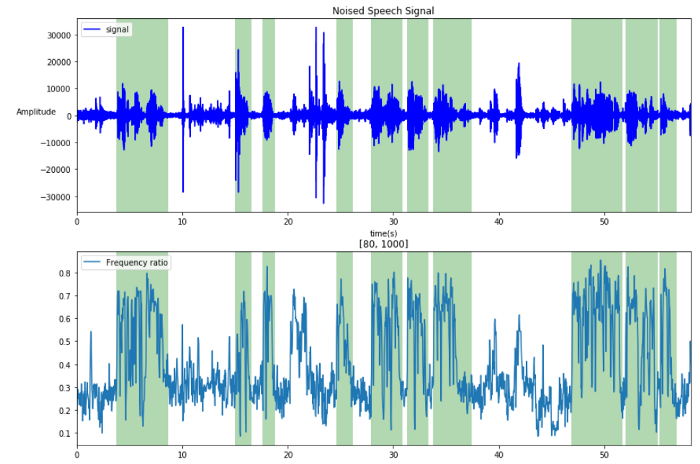
Spectrum Frequency Band Ratio
MFCC, FBANK, PLP
MFCC, FBANK, PLP are the most commonly used features for speech recognition.
There are concatenations of mathematical operations aiming to reduce and compress the number of information by keeping the most relevant ones.
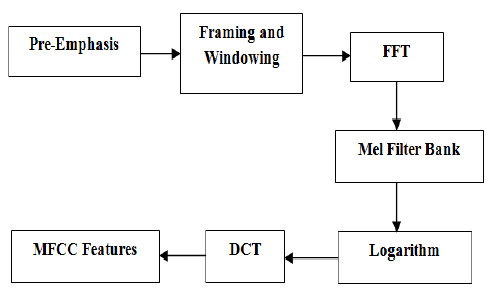
MFCC processing chain.
They return an array of values in opposition to the previous features.
Decision
Decision can be taken for each window either by setting threshold or using other decision algorithms such as machine learning.
A lot of applications like VoIP software use only energy feature because the speaker is close to the microphone without many interference, however in order to build robust and reliable VAD algorithm several features or composite features (such as MFCC, FBANK, PLP, …) are required.
Thresholds
The first approach is to use a threshold on the feature. It means that a window will be classified according to fact that the feature for this window is higher or lower than a given value. Problems are:
- How to determine the threshold ?
- How to accommodate context variation ?
- How many features ?
Static threshold
Static threshold are determined once and won’t vary overtime. They may be determined outside context for feature that won’t depend on environment like frequency-wise features. Or they can be determined at the beginning of the decoding on a few window that are known for being non-speech.
For example features such as Dominant Frequency or Spectrum Frequency Band Ratio can be determined once as speech frequencies won’t vary depending to the recording context.
On the other hand features such as Energy are bind to a specific context and setting a threshold may not fit real life situation (e.g. if you turn on the air conditioner mid recording you may pass the threshold for the rest of the recording).
Dynamic threshold
Dynamic threshold are threshold that will adjust over time. The goal is to accommodate changes. To do so the threshold is adjusted at every window to be higher than one classified as silence and lower than one classified as speech.
Our implementation is to compute the pondered mean between the mean of last x window of silence and the mean of the last x window of speech. For instance we use dynamic threshold for energy:
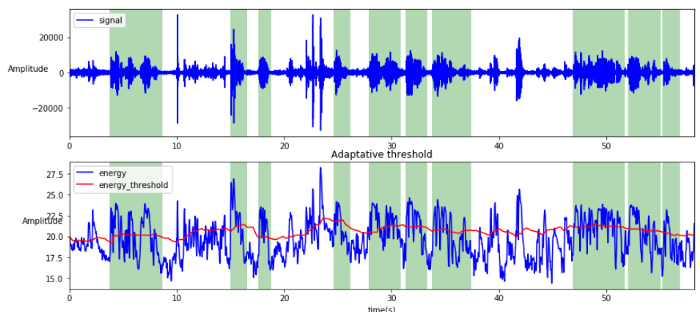
Decision rule using multiple features.
One feature is not always enough, in noisy condition it is better to use multiple features to differentiate speech.
Decision rule can be set using AND or OR rules. For example: classified as speech if energy and fundamental frequency are higher than their respective threshold. It can also be 2 out of 3 and so on. An other approach may be to set a weight for each feature and fix a threshold on the sum.
Machine Learning
An approach with amazing results is using machine learning classifier such as DNN to make a decision.
The algorithm is fed with (a lot of) labeled audio. Audio or audio features goes in one side and the label — 0 or 1 as it is a two-way classifier — goes to the other side … and you know the drill.
(It will probably be a subject for an other article as we tend to use Artificial Neural Network in more and more of our projects).
Competing Signals
Within the OpenPaaS::NG project we developed Hublot (a bot for virtual meeting) and we had to determine from multiple audio input which one is actively speaking. The goal was to relieve the back-end Automatic Speech Recognition by providing it only one stream instead of several. This approach came with the simplifying hypothesis that one person speak at a time.
The decision rules we used are: To be the active speaker 1) the Frequency Band Ratio must be up to a given threshold and 2) the Short Term Energy must be higher than all the other signals fulfilling the first condition. (From a second hypothesis that speech from one speaker has more energy than silence from all other speakers).
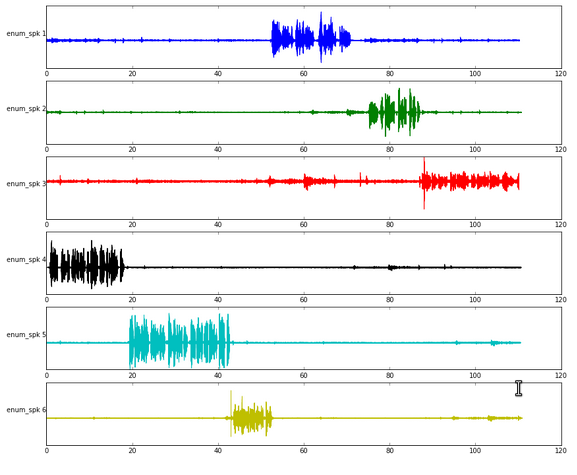
Multiple input to …
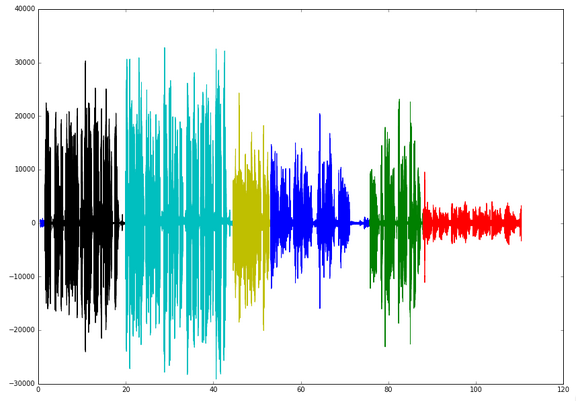
… to a single output.
Smoothing
Smoothing is important because speech isn’t only the production of sound it is also silences. Phonemes such as [p][t][k][b] are silence followed by sound, and the silence part may not be recognize as speech by the algorithm which will impact the performance of an Automatic Speech Recognition system.
One solution may be to increase the size of the analysis window. The other approach is to do an a posteriori smoothing.
Smoothing can be define as a set of rules (here the rules we use):
- To be considered speech there must be at least 3 consecutive windows tagged speech (192ms). It prevents short noises to be considered speech.
- To be considered silence there must be at least 3 consecutive windows tagged silence. It prevents too much cuts into speech which impact speech rhythm.
- If a window is considered speech the previous 3 windows and following 3 windows are considered speech. It prevents the loss of information at the beginning and at the end of a sentence.
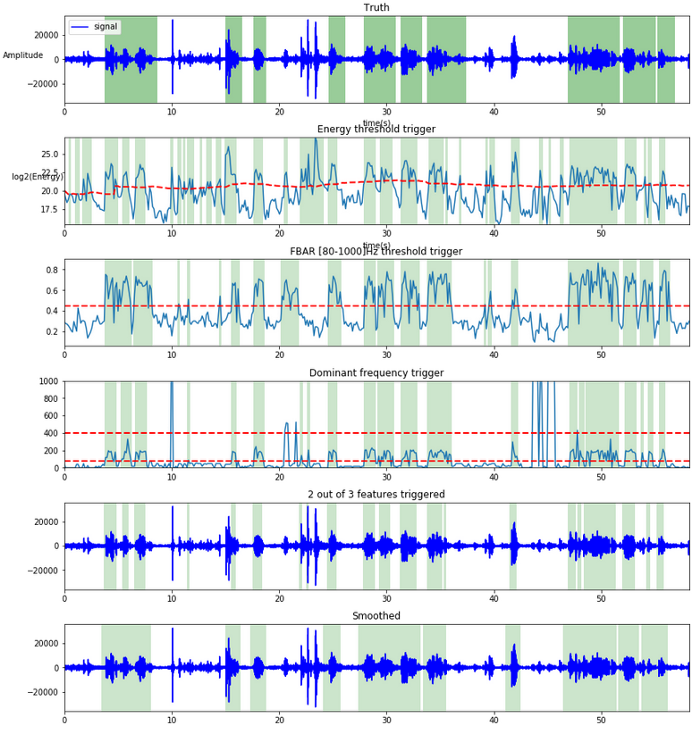
VAD with the 2 out of 3 rule.
On the diagram above you can see the VAD process step by step. First sub-diagram in the original signal annotated with the true speech segment. Next 3 diagrams are features used with their respective threshold. The 4th one is the output of the 2 out of 3 features and the last one is the result after smoothing.
The negative side is that the smoothing induce a delay between the recording and the actual detection. Less than a second but it can still be problematic.
Application
Here some example of our use of VAD.
Detect a single word.
For the detection of Wake-Up-Word we use the tool developed by Mycroft-AI to generate a GRU model : mycroft-precise. However the in-build tool to collect audio sample didn’t fit our requirements as we aim to collect a lot a samples from a lot a different people spread across multiple offices. So we made our own to be set on a raspberry pi with a touch-screen mounted on a terminal.
The original method of recording was:
In a console: press a key, wait a few second, say the word, press a key and repeat.
As it wasn’t really user-friendly we made a GUI with instruction, navigable with the touch-screen. Furthermore, pressing a key to signal the end of the record induced a lot of bad samples as user tended to forget to press the key immediately. Moreover, pressing the key produced a sound that can be eared on the record which is bad. So we introduced VAD to prevent the hazard of such problems happening. Because the recording takes place in a quiet room, in that case we used only energy to detect the speech.
As a result wrong samples dropped significantly.
Detect a sentence.
After the detection of the Wake-Up-Word the assistant is listening to a command and must detect when the user stop talking to stop the process. Here using energy alone wasn’t working properly because noises can append during the recording and must not be considered speech. Likewise, background noise is not known in advance. In that case we use two features to detect the end of speech:
- Energy with a dynamic threshold calculated prior and during the process.
- Frequency band ratio is computed during the recording as an additional condition.
With the decision rule : If silence is detected during more than 1 second, we consider that the sentence/command is over.
Conclusion
VAD techniques have a lot of applications for technologies related to speech processing. Implementation strongly depend on its purpose and on the environment it is meant to work in. Keep in mind that there is not yet an all-purpose VAD algorithm working in all situations for all languages, even if the arrival of deep learning voice detection classifier may mark a turning point, there are always specific situation where it may not work: Imagine wanting to detect people whispering in Xhosa in a car with opened windows.
An other point that have not been addressed is the computational power required to use those algorithm. Most of the computer nowadays can perform real time audio processing, but that may not be the case for embedded computer or smart object. It may restrain the approach and the quality of detection.
Thank you for your reading. Cheers !
P.S.: An interesting article from where I started is ‘A simple but efficient real-time voice activity detection algorithm. (LISSP 2009)’ which is worth the read.

Accessibility
visibility_offDisable flashes
titleMark headings
settingsBackground Color
zoom_outZoom out
zoom_inZoom in
remove_circle_outlineDecrease font
add_circle_outlineIncrease font
spellcheckReadable font
brightness_highBright contrast
brightness_lowDark contrast
format_underlinedUnderline links
font_downloadMark links
Reset all optionscached

We use cookies on our website to provide you with the most relevant experience by remembering your preferences and repeating your visits.
Cookies allow us to personalise content and advertisements, provide social media features and analyse our traffic. We also share information about the use of our site with our social media, advertising and analytics partners, who may combine this with other information you have provided to them or that they have collected through your use of their services.
By clicking "Accept All" you consent to the use of ALL cookies.
Cookies allow us to personalise content and advertisements, provide social media features and analyse our traffic. We also share information about the use of our site with our social media, advertising and analytics partners, who may combine this with other information you have provided to them or that they have collected through your use of their services.
By clicking "Accept All" you consent to the use of ALL cookies.
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely necessary for the proper functioning of the website. This category includes only those cookies that provide the basic functionality and security features of the website. These cookies do not store any personal information.
Functional cookies enable certain features to be performed such as sharing website content on social media platforms, collecting comments and other third party features.
Performance cookies are used to understand and analyse key performance indicators of the website, which helps to provide a better user experience for visitors.
Les cookies analytiques sont utilisés pour comprendre comment les visiteurs interagissent avec le site web. Ces cookies permettent de fournir des informations sur les mesures du nombre de visiteurs, le taux de rebond, la source de trafic, etc.
Advertising cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors to websites and collect information to provide personalised ads.
Other uncategorised cookies are those that are being analysed and have not yet been categorised.